

Nos pregunta Bernos a través de nuestro formulario de contacto (¡muchas gracias por plantearnos tu duda!) si conocemos maneras para poder almacenar una Web en un ordenador o un dispositivo portátil, para así poder consultarla sin necesidad de conexión a Internet.
La respuesta más rotunda: sí, es posible. La más acertada: es posible y además no es muy complicado, en función de lo que busques. Es posible almacenar una página (un artículo de Genbeta, por ejemplo) o almacenar, directamente, un sitio Web completo, desde la raíz a las páginas individuales. En concreto voy a presentaros tres formas de almacenar páginas Web para consultarlas sin conexión a Internet.
La más rápida y obvia: guardar los archivos HTML
Si lo que buscamos es almacenar las páginas Web (una página, no un sitio Web completo) en nuestro ordenador, para revisarlas y verlas igual que si estuvieramos conectados a Internet, estamos de suerte. Prácticamente todos los navegadores Web incluyen esta opción de serie.
En Firefox 8 la opción está en el botón de Firefox > Guardar como. En Safari y Chrome, clic en la llave inglesa> Guardar como. En Internet Explorer 9, clic en la llave inglesa, Archivo > Guardar como. En Opera deberemos pulsar en el botón de Opera, Guardar como.
Este comando generará o un archivo HTML (la página en sí) junto con una carpeta (con los archivos auxiliares como las imágenes, algún script…), o bien un archivo MHTML con todo el contenido guardado en él. Si es la primera opción debemos tener cuidado: conviene mover a la vez la carpeta y el archivo (tendrán el mismo nombre) para evitar perder las referencias a las imágenes, por ejemplo.
La principal desventaja de esto es que no podemos navegar el site sin conexión a Internet: no se guardan las páginas a las que enlaza la que hemos guardado. Pero tenemos dos opciones para guardar una Web completa o nada más que algunos niveles de enlaces.
Guardando un site completo: wget y HTTrack
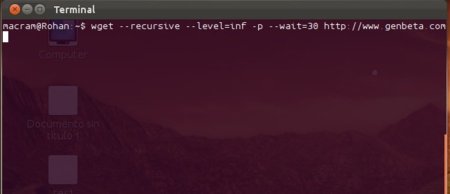
Si queremos guardar un site completo, por otra parte, tenemos dos opciones, y las dos completamente gratuitas. La primera está incluida por defecto en todas las distribuciones de Linux (y es instalable en Windows), y la otra es multiplataforma. La principal diferencia para nosotros será la interfaz.
wget es una herramienta terriblemente potente para descargar de la Web, y con un poco de imaginación es posible utilizarla para descargar tanto sites completos como páginas individuales. Vemos un ejemplo para el primer caso:
wget --recursive --level=50 -p --convert-links https://www.genbeta.comEse comando lo que hará es ejecutar wget de forma recursiva (para descargar la página y todas las páginas a las que enlaza), hasta el nivel 50 de profundidad (es decir, a lo que llegaríamos haciendo clic en máximo 50 enlaces), guardando los archivos auxiliares (para eso es el parámetro -p) y convirtiendo los enlaces a los de las descargas locales si se realizan (si no se mantienen las referencias a archivos remotos). Escribimos ese comando en la terminal, esperamos y… ya está. No se descargarán archivos de dominios distintos por defecto.
Si queremos hacer la copia de todo el sitio Web podemos poner inf como número de niveles a descargar, pero para evitar sobrecargar el servidor yo añadiría una opción extra: --wait=30 hará que wget espere 30 segundos entre descarga y descarga. wget puede ser usado para mucho más, pero para el propósito de ese artículo nos valdrá con esos parámetros. Si tenéis curiosidad, man wget será capaz de saciarla, os lo aseguro.
Si no queréis utilizar un comando de terminal, tenéis a vuestra disposición HTTrack, una aplicación que permite lo mismo, con muchísimas opciones de configuración e interfaz gráfica. Es una aplicación disponible para descargar desde su página Web y en los repositorios de las principales distribuciones de GNU/Linux.
Algunas páginas Web (como Genbeta, sin ir más lejos) no permiten el uso de este tipo de herramientas sobre sus páginas Web. Se deshabilita en el archivo robots.txt (dado que todas estas aplicaciones se identifican como lo que son). Debemos ser cuidadosos también con las opciones que marcamos, dado que este tipo de acciones utilizan mucho ancho de banda: tanto de bajada en nuestra línea como de subida en la del servidor, por no hablar de la carga de CPU en ambas máquinas.
Guardando artículos como PDF: Joliprint, impresoras PDF
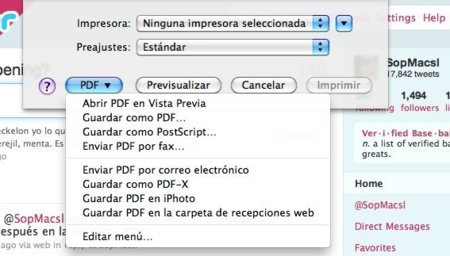
Si lo que buscamos es almacenar en nuestro PC un post como, por ejemplo, este que estáis leyendo, tenéis una alternativa aún mejor: guardarlo como PDF. Así además permitís imprimirlo en papel, si todavía queda alguien que lo haga. Esta forma es ideal si no necesitamos hiperenlaces (aunque hay algún software que admite guardar sites completos en formato PDF).
En Genbeta os hablamos hace tiempo de un bookmarklet llamado Joliprint que permite convertir el contenido de un post a PDF, incluso aplicando un estilo bastante elegante, que lo hace idóneo para impresión. Ese bookmarklet sigue activo, como podéis imaginar (de no ser así no lo mencionaría en el post).
Si queréis utilizar herramientas almacenadas en vuestro PC (y no en la nube) podéis no complicaros demasiado la vida e instalar una impresora PDF. Desde la oficial de Adobe hasta otras como doPDF hay todo un abanico de posibilidades, gratuitas, de pago, con publicidad, sin publicidad.
Yo personalmente en Windows recomiendo la que enlazo. En OS X ya se incluye una herramienta así, y en los distintos sabores de GNU/Linux y BSD es tan simple como instalar el paquete cups-pdf con nuestro gestor de paquetes (si es que no está ya instalado). El funcionamiento es idéntico en las tres plataformas: tan sólo es necesario usar la opción de imprimir en nuestro navegador, seleccionando esa impresora en el diálogo que aparece.
Si queréis transferir estos artículos a un lector de libros electrónicos es mejor combinar dos opciones: guardar el archivo HTML en nuestro equipo y convertirlo con Calibre. De esa forma se usará el formato más adecuado para cada dispositivo (el soporte de PDF en estos aparatos en ocasiones deja mucho que desear).
Como véis alternativas no faltan. Yo os he presentado tres, pero estoy seguro de que con imaginación podemos conseguir algunas más. No lo dudéis y compartidlas en los comentarios, seguro que lo agradeceremos todos.



Ver 18 comentarios
18 comentarios
richard-mx
Ahora resulta que por indicar que había un fallo en la redacción (que ya ha sido corregido) me gano negativos.
Típico, muuuuuuuuy típico de Weblogs SL.
richard-mx
Título: Tres formas de almacenar de forma offline una página o sitio web completo.
Body: En concreto voy a presentaros cinco formas de almacenar páginas Web para consultarlas sin conexión a Internet.
¿Tres o Cinco?
c3cg
Para mi como usuario de Firefox desde hace años la mejor manera es usar la extensión ScrapBook http://bit.ly/jg1w3c ya que esta permite guardar toda la paginas Web y administrarlas fácilmente como colecciones la verdad es que es de lo mejor.
DrivE ThrougH
Una opción muy interesante, no tanto para guardar una web completa, pero si ideal para imprimir un artículo, página web individual o lo que te apetezca, pudiendo excluir la publicidad, los comentarios y aquello que no te interese imprimir es PRINTWHATYOULIKE.
Podéis encontrar el script aquí: http://www.printwhatyoulike.com/
desierto
En mi opinión, la mejor opción para un sitio web completo:
http://sourceforge.net/projects/getleftdown/
SL multiplataforma...
stranno
HTTRACK + HTML Help Workshop, sin duda
48186
De verdad que se complican mucho la vida. Yo sólo presiono CONTROL +S y así guardo los artículos que más me interesan de GENBETA para leerlos en el avión cuando viajo a Canadá. Saludos.
Enrique
Yo en windows utilizo el teleport, que además le puedes decir que se identifique como internet explorer para saltarse todas las restricciones.
En El Jardin de Eva
Gracias por la aportación. Voy a utilizarlas a ver que tal me va. Gracias.
MGeek
Google Chrome ya permite de forma nativa imprimir (exportar) una página web a un archivo en PDF.
Así ya no hace falta instalar impresoras virtuales y ese rollo. ;)
absalom
existe tambien pagesnap, que es similar a joliprint; pero esta es una web donde debes ingresar la url a guardar en pdf... http://www.pagesnap.net